

Philip Williams
on 25 August 2022
Modern organisations have become reliant on their IT capabilities, and at the heart of that infrastructure is a growing need to store data. Be it transactional databases, file shares, or burgeoning data lakes for business analytics.
Traditionally, storage needs have been catered to by big iron hardware vendors, but over the last decade, more and more organisations have turned to open-source solutions such as Ceph running on commodity hardware. In this post we will introduce Ceph, and some of the reasons why organisations choose it.
Choosing a storage solution
Here at Canonical we are often asked, where should I store my data? And largely, the answer to the question depends on a few factors:
- Performance and latency requirements – For general purpose VM boot images, storage of large file shares, or huge data lakes, a scale out system typically makes the most sense, as the system can grow both performance and capacity over time. However, if there is a workload that has very specific sub-ms latency requirements (driven by a business Service Level Objective (SLO)), or a very high IO density (IO/GB), then a proprietary system may make more sense.
- Budget – With an unlimited budget it really is possible to design a storage system to suit all needs, but, being pragmatic, this is never the case. Sometimes it makes more sense to choose a scale out system vs a proprietary scale-up system and vice-versa, depending on the balance between performance and budget.
- Scaling – When we look to design a storage system, we shouldn’t just think about the amount of capacity needed now, but also consider the next 6-36 months into the future. For datasets with well bounded growth expectations this is relatively easy, and can mean that scale-up systems are suitable. For other datasets ,it can seem like guesswork, which makes the ease of scaling in a scale-out system more attractive.
- Locality – Maybe, you are building a private cloud, so we can consider creating a hyper-converged system, where storage and compute share the same nodes and scale together. Alternatively, dedicated storage nodes where storage can scale independently of compute resources could work. It may even be the case that you are using compute from one or more public clouds, but want to control your data storage costs by building a cloud-adjacent storage system in a co-location facility.
And finally, remaining pragmatic, there may already be an existing system that has plenty of operational life remaining (both technically and also financially) that we can integrate into a private cloud.
What’s the modern solution?
To meet the dynamic needs of modern enterprises, more often than not, we recommend the open source scale out storage solution Ceph. It is designed to address block, file and object storage needs from a single unified cluster. Use cases for Ceph range from private cloud infrastructure (both hyper-converged and disaggregated) to big data analytics and rich media, or as an alternative to public cloud storage.
The highly scalable architecture of Ceph means that it is commonly adopted for high-growth block storage, object stores, and data lakes. Physical hardware is treated like a commodity, and all of the intelligence to scale and protect your data is entirely software driven. This makes Ceph ideal for cloud, Openstack, Kubernetes, and other microservice and container-based workloads, as it can effectively address large data volume storage needs.
How does Ceph work?
The main advantage of Ceph is that it provides interfaces for multiple storage types within a single cluster, eliminating the need for multiple storage solutions or any specialized hardware, thus reducing management overheads. A typical cluster is built with standard servers, and two Ethernet networks, one for client access, and one internal to the cluster.
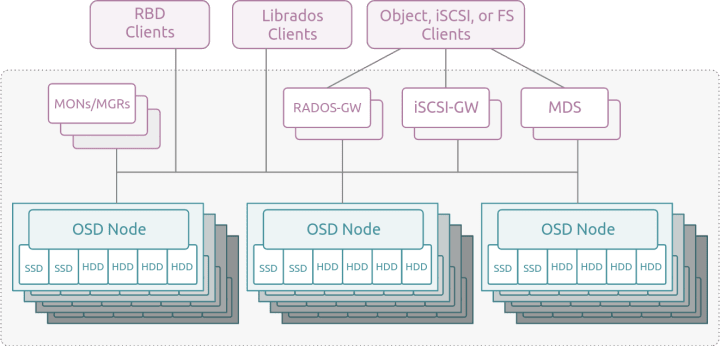
What components make up a Ceph storage cluster?
- Cluster monitors (ceph-mon) maintain the map of the cluster, and its state, keeping track of active and failed nodes, configuration, and information about data placement and manage authentication.
- Managers (ceph-mgr) gather cluster runtime metrics, enable dashboard capabilities, and provide an interface to external monitoring systems.
- Object storage daemons (ceph-osd) are responsible for storing data in the Ceph cluster and handle replication, erasure coding, recovery, and rebalancing. Conceptually, an OSD can be thought of as a slice of CPU/RAM and the underlying SSD or HDD.
- Rados Gateways (ceph-rgw) provide object storage APIs (S3 and swift) via http/https.
- Metadata servers (ceph-mds) store metadata for the Ceph File System, mapping filenames and directories of the file system to RADOS objects and enabling the use of POSIX semantics to access files.
- iSCSI Gateways (ceph-iscsi) provide iSCSI targets for traditional block storage workloads such as VMware or Windows Server.
Ceph stores data as objects within logical storage pools. A Ceph cluster can have multiple pools, each tuned to different performance or capacity use cases. In order to efficiently scale and handle rebalancing and recovery, Ceph shards the pools into placement groups (PGs). The CRUSH algorithm defines the placement group for storing an object and thereafter calculates which Ceph OSDs should store the placement group.
How to get started
Getting started with Ceph is easy. You can create a small cluster with a handful of nodes (or even VMs for testing only) to try it out. Check out the install guide for more details..
Conclusion
Ceph is the answer to scale out open source storage, and can meet ever changing business needs across private and public clouds, as well as media content stores and data lakes. Its multi-protocol nature means that it can cater to all block, file and object storage requirements, without having to deploy multiple isolated storage systems. Ceph clusters can be designed to suit any workload, meet budget requirements, and importantly, upgraded and expanded on the fly with no downtime.
We will continue this blog series with an article diving deeper into how MAAS, Juju and Charmed Ceph make Ceph easy to deploy and operate.
Resources
Read about Ceph storage on Ubuntu
Watch the webinar – Ceph for Enterprise
Watch the webinar – Reduce your storage costs with Ceph
Watch the webinar – Building cost-efficient open source cloud operations


